Welcome to FTX's Blog!
本站记录我的七七八八的编程之旅沿途风景!-
C++常用容器
- 这里我们介绍一下 C++ 算法竞赛中的STL常用的容器和函数用法:
- 一.vector容器 二.pair容器 三.queue容器 四.deque容器 五.priority_queue容器
- 六.set容器 七.map容器 八.string容器 九.stack容器 十.tuple容器
这里我们介绍一下 C++ 算法竞赛中的STL常用的容器和函数用法:
在这个C++ STL容器运用的部分,我们只简单的介绍常用的语法和运用,每一个容器的结束也都会举与容器有关的题目来实践运用。如有补充不全或者错误,还请多包涵。
一.vector容器 二.pair容器 三.queue容器 四.deque容器 五.priority_queue容器
六.set容器 七.map容器 八.string容器 九.stack容器 十.tuple容器
-
部署和使用makedown写jekyll
关于jekyll 建站前的碎碎念: 记得我了解jekyll还是在一次无意间刷小破站看到的,但是当时看到的并不是jekyll,是Hexo这个框架。为什么选择jekyll,因为在Comments看到一个blog评论了一句“jekyll不香吗?” 我当时就去搜索了一些相关jekyll的资料来查阅这个建站框架。一查惊艳到我了,jekyll的模型框架对于一个想要搭建一个小型的web或者一个分享知识的个人blog网站真是很不错。搭建好之后对于写文章也很友好,也有利于维护。具体关于jekyll可以自行官网了解:jekyll 接下来我就简单具体介绍一下 jekyll 框架的用法:
-
基于yolov5的老人摔倒识别系统
项目介绍:
基于yolov5这个机器学习模型,完成了老年人摔倒大量数据集的查找,以及对老年人摔倒行为的数据集进行标签标注,按照预期,训练数据集得到了理想的数据训练模型,准确的检测了老人摔倒的这一行为,有效的检测了老年人日常的行为安全。
项目源地址:
目前项目已经在Github开源(包括唐卡图像数据集),如果有需要的可自行下载。如果该项目可以帮助到您,麻烦您给我一个免费的star!!!
-
前端期末项目
这个项目是我在大二上学期开设的Web前端课程学习期末的一个答辩项目。大家可以借鉴参考使用。附上项目源码地址https://github.com/futingx/awesome-Web-Design.git
技术栈:HTML5,CSS,Javascript
以下是该项目所具有的功能模块:
- 背景特效:
- 使用JavaScript实现了流星雨背景效果。
- 每个页面背景都采用了线性渐变效果。
- 侧边栏功能:
- 顶部侧边栏包含常见的网页功能。
- 左侧侧边栏有点击事件的彩蛋功能。
- 自我介绍模块:
- 使用JavaScript实现了打字机效果的自我介绍模块。
- 实时和环绕时钟:
- 使用JavaScript实现了两颗两色流星的实时和环绕时钟效果。
- Logo精灵图选择:
- 合理选择了Logo精灵图。
- 轮播图与控制:
- JavaScript实现了轮播图的手动和自动播放控制。
- 3D图片盒子:
- 使用HTML和CSS实现了附有人物介绍的3D图片盒子。
- 锚点侧边栏:
- 右侧侧边栏包含了顶部返回等功能的锚点。
- 新闻栏:
- 实现了带有页面间链接的新闻栏。
- 锚点新闻栏中的渐变按钮跟随鼠标移动。
- 滑块验证:
- 使用JavaScript实现了基本的滑块验证功能,滑动到指定位置判断验证成功与否。
- 留言板:
- 实现了留言、删除和实时时间记录等功能的留言板。
- 视觉设计:
- 结合CSS样式和动态JavaScript元素,实现了美观和吸引人的网页设计。
- 背景特效:
-
摩天轮动画的实现揭秘
摩天轮动画的实现揭秘
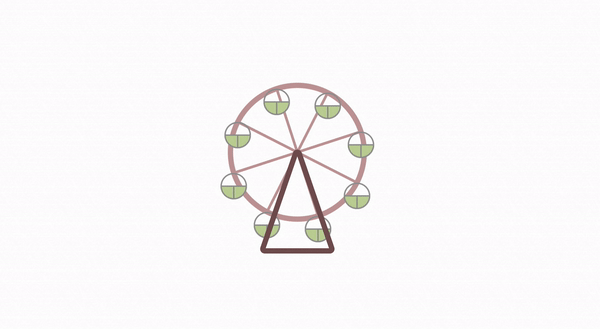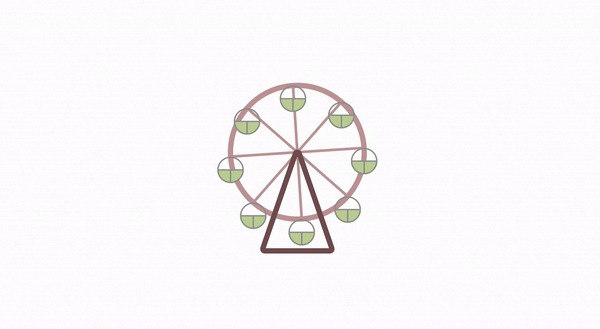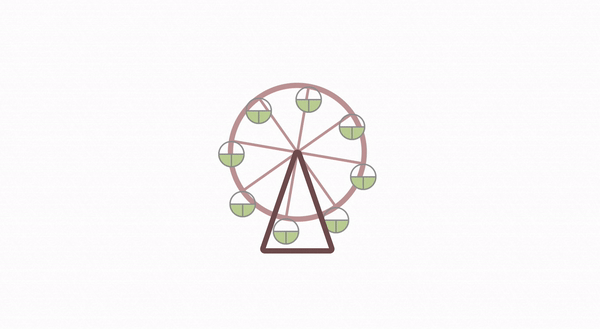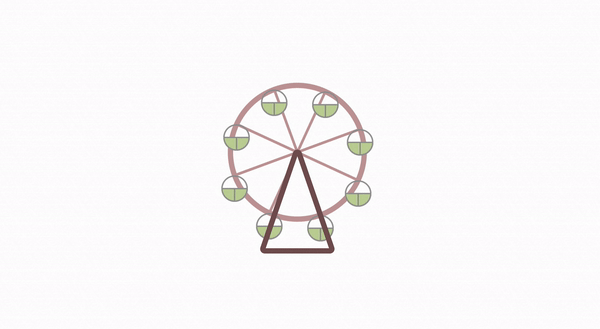
恰好近期业务上开发了类似这样的摩天轮动画,我将其中的实现原理分享给大家。摩天轮动画主要分为 2 部分,一个是摩天轮上每个房间位置布局,另一个就是旋转动画了。
-
vscode 插件 markdown-schedule-snippet
起因
不知道大家是怎样安排自己的日常计划的,我习惯是建立一个仓库,按照年/周记录在 markdown 里,平时这个仓库也写点简单的 demo,目录类似如下:
week ├── 2016 ├── 2017 ├── 2018 │ ├── 20180102.md │ ├── 20180108.md │ ├── 20180115.md │ ├── 20180122.md │ ├── 20180126.md │ ├── ... │ ├── ... │ ├── ... │ ├── 20181007.md │ ├── pixi.md │ ├── schedule.md │ ├── temp.css │ ├── temp.html │ ├── temp.js │ ├── temp.json │ └── temp.md ├── package.json └── yarn.lock
-
从设计师和开发的角度使用 lottie

简介
lottie 是一个可以轻易的给各种 native app 添加高质量动画的类库。可以在 iOS、Android 和 React Native 实时渲染 After Effects 动画,就像使用静态图片一样容易。上图即为 lottie 的 logo。
简单的说,lottie 动画制作的流程是,通过 Bodymovin 扩展将 AE 动画导出为 json 数据,然后再将这个 json 渲染在客户端或者 web 端。如下图:
-
canvas动画之速度与加速度
本文将开始讲述动画编程的部分,会从基本的运动属性开始:速度、向量和加速度
- 速度
- 加速度
-
canvas 绘图技术与图片处理
本文将讲述一些 canvas 相关的绘图技术,其中包括:
- 绘图 API
- 图片加载
- 像素处理
-
对这个 jekyll 博客主题的改版和重构
本文主要说明对这个博客主题的改版和代码重构的过程。这个简洁高雅的博客主题受到了很多朋友的喜欢。在写第一版界面时,我对前端并不是很熟悉,对
Jekyll也不熟悉。现在距离当时也一年了,对自己当时写的代码也不太满意了,同时Jekyll如今也已经升级了,目前最新版为3.1.2。因此我在临近毕业尚未入职前做一下博客主题的代码重构和改版吧。主要想做这些事情有:添加归档,添加标签,添加分类页面,主页显示文章摘要,代码去除 jQuery 和 BootStrap,优化移动端显示,将所有变量写入配置文件
_config.yml中等。再优化一些细节吧。希望更多人会喜欢。