🚀 动手做了一个服装客服 RAG 系统
顺便理清了 RAG 开发的完整流程
“做这个项目之前,我对 LangChain、RAG 向量检索这些概念只停留在”听说过”的层面。学了课程之后,总觉得少点什么——没有真正跑过一个完整的东西,心里不踏实。” 本文记录我是怎么从零搭建这套系统的,以及中途踩的几个坑。
📋 项目概述
需求背景
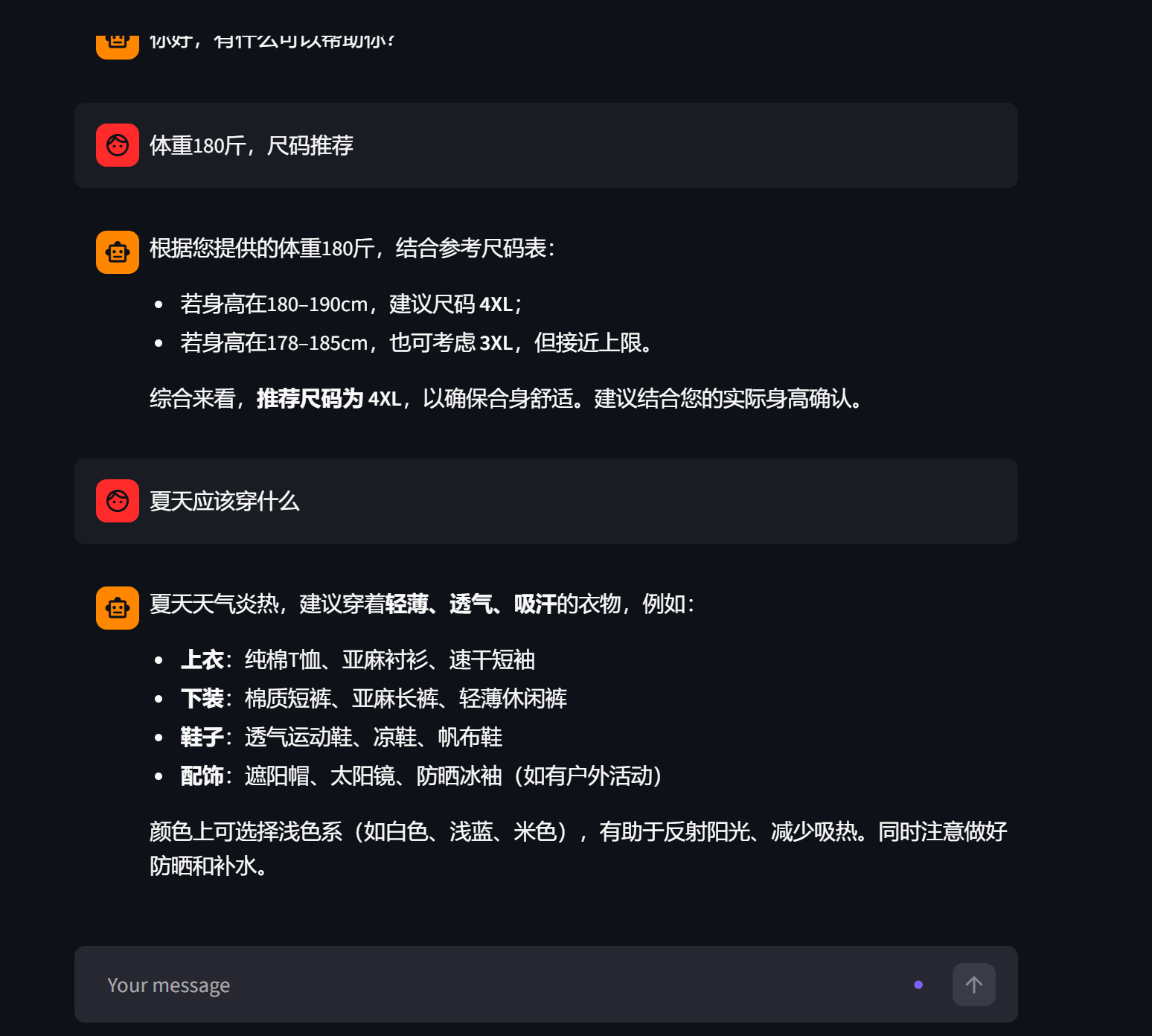
服装电商客服常被问到的问题其实很集中:
| 问题类型 | 示例 |
|---|---|
| 尺码咨询 | 身高、体重 → 对应尺码推荐 |
| 颜色选择 | 这件衣服什么颜色好看? |
| 洗涤护理 | 这件衣服怎么洗?能用洗衣机吗? |
这些问题的答案都在商品详情页里,但如果每次都让人工客服去翻资料,效率太低。
技术方案
用户提问 → 知识库检索 → 大模型生成答案 → 返回用户
这基本就是 RAG(Retrieval-Augmented Generation)的标准流程。区别在于,这次我用的是 LangChain + Chroma 构建完整的知识库问答链路,而不是调几个 API 敷衍了事。
📁 项目结构
写代码之前,先把项目结构定下来:
P4_RAG项目实战/
├── config_data.py ⚙️ 配置文件:模型名、向量库参数、分块策略
├── knowledge_base.py 📚 知识库服务:文件上传、MD5去重、文本向量化入库
├── vector_stores.py 🔍 向量库服务:检索器封装
├── rag.py ⚡ RAG 核心:检索链 + 对话历史 + 提示词模板
├── file_history_store.py 💾 对话历史:基于 JSON 文件的长期记忆
├── app_file_uploader.py 📤 Streamlit 知识库上传页面
├── app_qa.py 💬 Streamlit 客服对话页面
├── chat_history/ 📂 对话历史存储目录
├── chroma_db/ 🗄️ Chroma 向量数据库本地存储
└── data/ 📄 知识库原始文本(尺码、颜色、洗涤)
核心模块只有三个:知识库构建、向量检索、RAG 链
一、🏗️ 知识库怎么构建
知识库是 RAG 的地基。如果这一步没做好,后面的检索就是在垃圾堆里找东西。
1️⃣ 原始数据
我把业务知识整理成了三个 TXT 文件:
尺码推荐(尺码推荐.txt):
身高:155-165cm,体重:75-95斤 → 建议尺码 S
身高:160-170cm,体重:90-115斤 → 建议尺码 M
身高:165-175cm,体重:115-135斤 → 建议尺码 L
...
颜色推荐(颜色选择.txt) 和 洗涤说明(洗涤养护.txt) 也类似。
2️⃣ MD5 去重机制
用户可能反复上传同一份文件,如果每次都重新入库,既浪费向量计算资源,也会造成检索结果重复。
# 核心逻辑(knowledge_base.py)
def upload_by_str(self, data: str, filename: str):
md5_hex = get_string_md5(data)
if check_md5(md5_hex):
return "[跳过] 内容已经存在知识库中"
# 超过阈值才分割,短文本直接入库
if len(data) > config.max_split_char_number:
knowledge_chunks = self.spliter.split_text(data)
else:
knowledge_chunks = [data]
self.chroma.add_texts(knowledge_chunks, metadatas=[...])
save_md5(md5_hex)
return "[成功] 内容已经成功载入向量库"
3️⃣ 文本分割策略
RecursiveCharacterTextSplitter 按照优先级依次尝试分段:
| 参数 | 值 | 说明 |
|---|---|---|
| chunk_size | 1000 | 每段最多 1000 字符 |
| chunk_overlap | 100 | 段之间重叠 100 字符 |
| separators | 见右侧 | ["\n\n", "\n", ".", "!", "?", "。", ...] |
重叠的设计很关键——很多句子被拦腰切断时语义会变得残缺,加一点重叠能保证检索到的片段是完整的。
4️⃣ 向量数据库选型
我选的是 Chroma,原因是:
- ✅ 轻量
- ✅ 本地持久化
- ✅ 开源
# vector_stores.py
self.vector_store = Chroma(
collection_name="rag",
embedding_function=DashScopeEmbeddings(model="text-embedding-v4"),
persist_directory="./chroma_db",
)
嵌入模型用的是阿里云 text-embedding-v4。
二、⚙️ RAG 链怎么串
1️⃣ 整体链路
用户提问
│
▼
[RunnablePassthrough] 透传输入
│
▼
[向量检索] 从 Chroma 拉回 Top-1 相关文档
│
▼
[format_document] 把检索到的文档拼成上下文字符串
│
▼
[prompt_template] 上下文 + 历史记录 + 用户输入 → 组装提示词
│
▼
[ChatTongyi] 调用通义千问 qwen3-max 生成回答
│
▼
[StrOutputParser] 解析模型输出为纯文本
# rag.py
chain = (
{
"input": RunnablePassthrough(),
"context": RunnableLambda(format_for_retriever) | retriever | format_document
}
| RunnableLambda(format_for_prompt_template)
| self.prompt_template
| self.chat_model
| StrOutputParser()
)
2️⃣ 提示词模板
self.prompt_template = ChatPromptTemplate.from_messages([
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。"),
("system", "并且用户对话历史记录如下:"),
MessagesPlaceholder("history"),
("user", "请回答用户提问: {input}")
])
这里用了
MessagesPlaceholder,让对话历史能以标准格式注入。
3️⃣ 对话历史管理
多轮对话时,大模型需要知道之前聊了什么。
# file_history_store.py
class FileChatMessageHistory(BaseChatMessageHistory):
def __init__(self, session_id, storage_path):
self.file_path = os.path.join(storage_path, session_id)
def add_messages(self, messages: Sequence[BaseMessage]) -> None:
all_messages = list(self.messages)
all_messages.extend(messages)
new_messages = [message_to_dict(message) for message in all_messages]
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump(new_messages, f)
@property
def messages(self) -> list[BaseMessage]:
try:
with open(self.file_path, "r", encoding="utf-8") as f:
return messages_from_dict(json.load(f))
except FileNotFoundError:
return []
这样即使用户关闭页面重新打开,只要 session_id 不变,历史记录依然在。
三、💻 Web 界面怎么写
用 Streamlit,两个页面分别负责不同的事情。
📤 知识库上传页面
# app_file_uploader.py
uploader_file = st.file_uploader(
label="请上传TXT文件",
type=['txt'],
accept_multiple_files=False,
)
if uploader_file is not None:
text = uploader_file.getvalue().decode("utf-8")
result = st.session_state["service"].upload_by_str(text, file_name)
st.write(result)
💬 客服对话页面
# app_qa.py
if "message" not in st.session_state:
st.session_state["message"] = [{"role": "assistant", "content": "你好,有什么可以帮助你?"}]
for message in st.session_state["message"]:
st.chat_message(message["role"]).write(message["content"])
prompt = st.chat_input()
if prompt:
st.chat_message("user").write(prompt)
st.session_state["message"].append({"role": "user", "content": prompt})
res_stream = st.session_state["rag"].chain.stream({"input": prompt}, config.session_config)
st.chat_message("assistant").write_stream(res_stream)
流式输出(
stream=True)让用户能看到文字逐字出现,体验比等模型全部生成再返回好很多。
四、⚠️ 中途踩的几个坑
说起来都是小问题,但当时卡了不少时间。
| 坑点 | 问题 | 解决方案 |
|---|---|---|
| 逗号遗漏 | MessagesPlaceholder 后面少了逗号 | LangChain 的 ChatPromptTemplate.from_messages 对列表格式要求严格 |
| 参数格式 | chain.invoke 直接传字符串 | 必须以字典形式传入:{"input": "..."} |
| 参数名写反 | history_messages_key 名字对不上 | 仔细对照文档,名字拼写要一致 |
五、📝 总结
这个项目麻雀虽小,五脏俱全:
✅ 知识库构建
✅ 向量检索
✅ RAG 链编排
✅ 对话历史管理
✅ 前端界面
核心经验
-
知识库质量决定了检索上限
脏数据、重复数据、未分割的长文本都会让检索结果变差 -
提示词模板要随着场景调整
加上”以参考资料为主”这样的约束,回答的专业性会明显提升 -
流式输出不只是技术优化
用户感知到的响应时间缩短了,体验提升是实实在在的 -
LangChain 文档需要耐心读
很多坑其实是文档里有明确说明的
下一步计划
- 向量数据库换成 Milvus 或 Qdrant,支持更大规模数据
- 接入图片理解能力,让客服能识别商品截图
- 远期目标:多模态 RAG
如果你也在从零做 RAG 项目,欢迎交流。我的感受是:看十遍文档不如亲手跑通一个项目,很多”道理”会在代码报错的时候突然变得清晰。
—— FTX 于 2025